Emergence of Collective Intelligence through Large-Scale Multi-Agent Cooperation in Lux-AI

Overview
In the 1v1 turn-based game Lux-AI, we implemented a centralized cooperative strategy to control massive numbers of agents. Through this approach, we observed the emergence of complex macro-level tactics as these agents competed for limited resources, pursued urban development, and confronted the challenges of the long night. The implementation of this centralized collaboration strategy utilized distributed reinforcement learning algorithms and Pixel-to-Pixel modeling. During the training process, the AI's behavioral evolution primarily unfolded in the following stages:
| Mastering Fundamental Skills
The AI learned to gather resources, construct cities near resource nodes, transfer energy between cities, and upgrade research points to access higher-tier resources.

| Developing Sustainable Coexistence
The AI evolved to optimize resource management, balancing urban expansion with resource allocation. Instead of rapid but unsustainable city growth—which often led to mass city collapse due to nighttime resource shortages—it achieved a state of mutual non-aggression and sustainable development between opposing AIs.
 | Emergence of Aggressive Strategies
| Emergence of Aggressive Strategies
The AI began exploiting game mechanics (e.g., the map's symmetrical layout) to efficiently monopolize resources and constrain opponent living space. Early-game tactics included defensive positioning near critical resources to prevent opponent collection, while dispatching troops to disrupt the opponent's city connectivity.
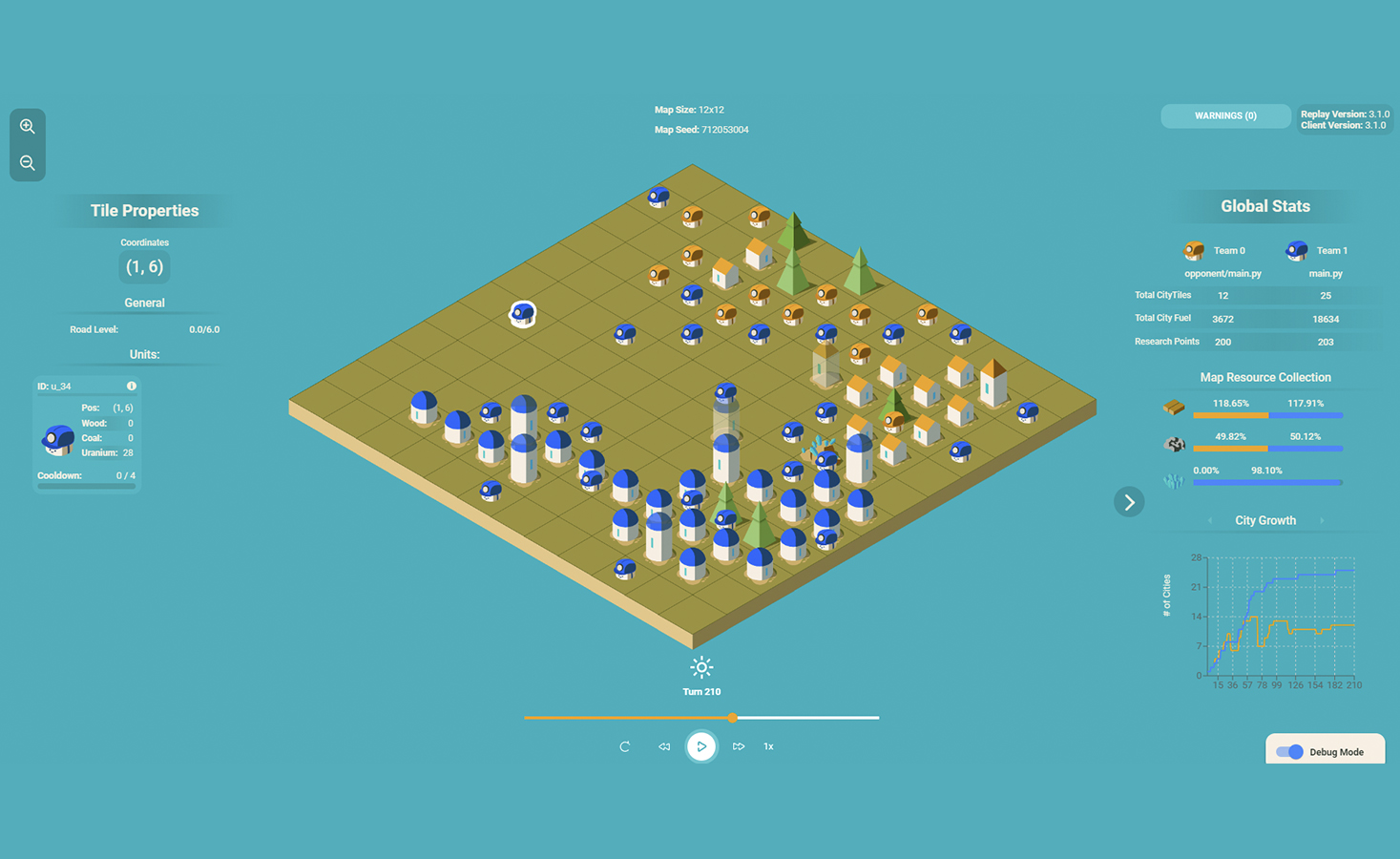
 | Complex Macro-Level Strategies
| Complex Macro-Level Strategies
The AI gradually discovered more sophisticated collaborative schemes, leading to unexpected macro-strategies. For instance, as shown in the figure, the blue AI learned to arrange its units in a Gomoku-like diagonal formation—a highly efficient pattern for maximizing spatial control with minimal units.
 In the Lux-AI environment, where macro and micro strategies must intertwine, we discovered that combining Pixel-to-Pixel modeling, distributed reinforcement learning frameworks, and curriculum learning enables the emergence of sophisticated team strategies without explicit cooperation mechanisms. This approach facilitates spontaneous cooperation among massive numbers of agents and the emergence of macro-level strategies. Furthermore, our solution outperforms the current SOTA approach (the winning model of Kaggle's Lux-AI competition) with a 90% win rate.
In the Lux-AI environment, where macro and micro strategies must intertwine, we discovered that combining Pixel-to-Pixel modeling, distributed reinforcement learning frameworks, and curriculum learning enables the emergence of sophisticated team strategies without explicit cooperation mechanisms. This approach facilitates spontaneous cooperation among massive numbers of agents and the emergence of macro-level strategies. Furthermore, our solution outperforms the current SOTA approach (the winning model of Kaggle's Lux-AI competition) with a 90% win rate.
For further details, please visit: [Academic Paper] [Open-Source Code] [LUX Environment]
Environment Introduction
Lux-AI is a 1v1 turn-based real-time strategy game where two teams employ AI to control units and cities. Units collect resources to build cities, while both cities and units require resources to survive the night. The ultimate goal is to retain as many cities as possible by the end of the game. Teams must balance resource gathering and city development while combating the encroaching darkness. During the day, they must aggressively collect resources to prepare for the coming night while expanding their cities. However, the AI must also plan carefully—overexpansion risks resource depletion, causing cities to collapse when night falls.
Massive Multi-Agent Environment
The key challenge in the Lux-AI environment lies in controlling a massive number of agents (up to 1,000) with dynamic population changes. The agent count fluctuates through a cycle of units constructing cities and cities generating new units, while also potentially experiencing sharp declines due to energy shortage. This setup introduces several challenging research problems in reinforcement learning.
| Agent Collaboration: Cooperation among agents is a critical issue in both gaming and reinforcement learning. Current solutions often rely on manually designed credit assignment strategies, but their complexity scales exponentially with the number of agents.
| Exploding Joint Action Space: As the number of agents grows, the joint action space expands exponentially.
| Sparse Rewards: The sparse reward problem makes exploration during training highly difficult.
Abstraction of RTS Games
Lux-AI can be viewed as a simplified version of traditional Real-Time Strategy (RTS) games like StarCraft II, but with a key difference: it is designed for AI control rather than human players.
On one hand, RTS games typically require players to execute micro-level actions (e.g., gathering, building, and combat) to achieve victory. However, the true challenge lies in when, where, and how to perform these actions—essentially, the player’s macro-level planning ability. In this sense, Lux-AI serves as a streamlined RTS environment.
On the other hand, the core distinction is that conventional RTS games employ a hierarchical execution framework: human players issue high-level commands to groups of units, which then autonomously execute subtasks based on built-in game logic. In contrast, Lux-AI lacks such hierarchical structures and low-level execution logic, making it impractical for human players but ideal for AI research.
Methodology
We employs self-play training strategies and the PPO algorithm [3], combined with GAE (Generalized Advantage Estimator) [4] for advantage function estimation. The algorithm is implemented based on our distributed reinforcement learning framework, with a Pixel-to-Pixel policy network [1,2] that enables global information sharing and cooperation through a deep convolutional network similar to ResNet [5]. The input part consists of image features of the map size, and the output part represents the actions for each pixel. To address the challenges of sparse rewards and exploration, we designed a three-phase curriculum learning scheme.
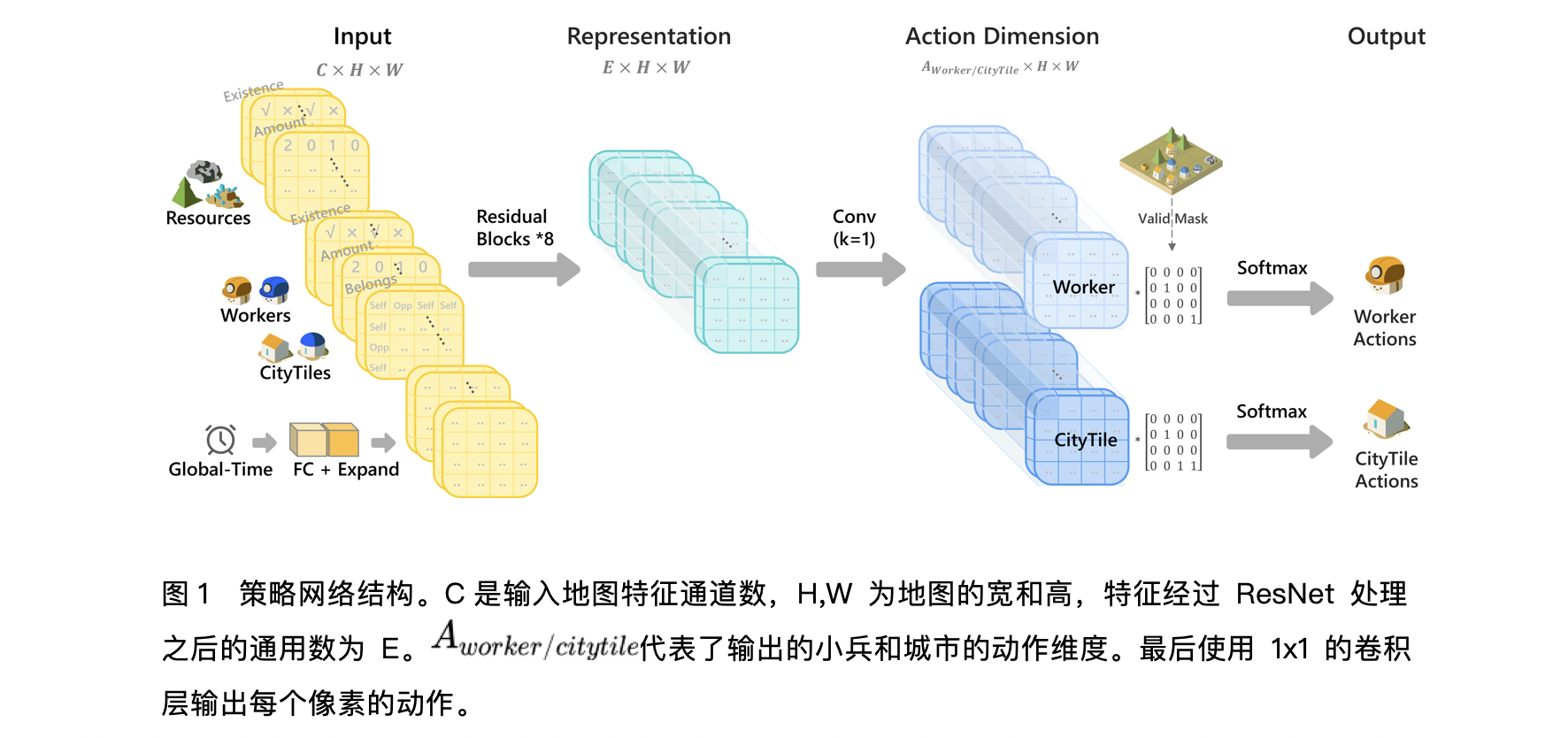
Pixel-to-Pixel Modeling Scheme
In the Pixel-to-Pixel modeling scheme, we employ a centralized training approach to coordinate a large number of agents. Specifically, the model takes the entire map's image as input and outputs an action for each pixel, as illustrated in the diagram. The input image has dimensions (C × H × W), where C denotes the number of channels encoding information about the player's team, the opponent's team, and global state. H and W represent the map's height and width. For example, one channel indicates the resource information, where the (ath, bth) pixel represents the wood resources at that location. A dedicated channel in the output image represents the probability distribution over actions for each pixel. Simultaneously, an action mask is computed based on the current game state—for instance, to determine the legality of an action type at a pixel given the number of units present—thereby facilitating more efficient exploration. The policy network is built on a ResNet convolutional backbone, comprising 8 residual units, each containing two convolutional layers with 128 channels and a kernel size of 5. The total parameter count is approximately 23.8 million, whereas the Toad Brigade [1] policy network employs 24 residual units. In addition to the policy output, we include a fully connected network to estimate the value function in the actor-critic framework.
Advantages of Centralized Training
In current multi-agent reinforcement learning, distributed modeling is the predominant approach due to its efficiency and scalability. However, in Lux-AI, the vast number of units and the inherently dynamic nature of the game pose significant challenges for credit assignment. This is why we adopt a centralized approach—similar to how human players issue commands to each city and unit in an RTS game. Nonetheless, in Lux-AI, a centralized agent must determine actions for all units simultaneously, which is considerably more complex than traditional RTS settings. This complexity arises from the enormous joint action space and the fluctuating number of units. To address these challenges, we utilize convolutional layers for local parameter sharing within the Pixel-to-Pixel architecture, greatly enhancing learning efficiency and exploration in the action space. Additionally, stacking multiple convolutional layers expands the receptive field, enabling effective information sharing across all pixels and promoting coordinated decision-making.
Advantages of Pixel-to-Pixel Modeling
Intuitively, while the Pixel-to-Pixel architecture represents a centralized policy network, it leverages the advantages of both centralized and decentralized approaches—maintaining learning efficiency while enabling effective cooperation.
On one hand, instead of employing separate fully connected layers to control units and buildings at each pixel, we utilize convolutional parameter sharing. This approach mirrors decentralized training by using a shared policy network to coordinate all agents.
On the other hand, we implement a single network that maps observations directly to actions, enabling the system to implicitly learn cooperative behaviors and thereby circumvent explicit credit assignment issues. By stacking sufficiently deep convolutional layers, information can be shared across all pixels, allowing each to make informed decisions based on a global understanding of the state.
Curriculum Learning
The curriculum learning process is divided into three phases, guiding agent learning from simple to complex tasks.
| Phase 1: Dense Rewards with Manual Design
Initially, we encourage agents to learn fundamental skills, such as constructing city buildings around resources. Four behaviors and their corresponding rewards are shown in the table.
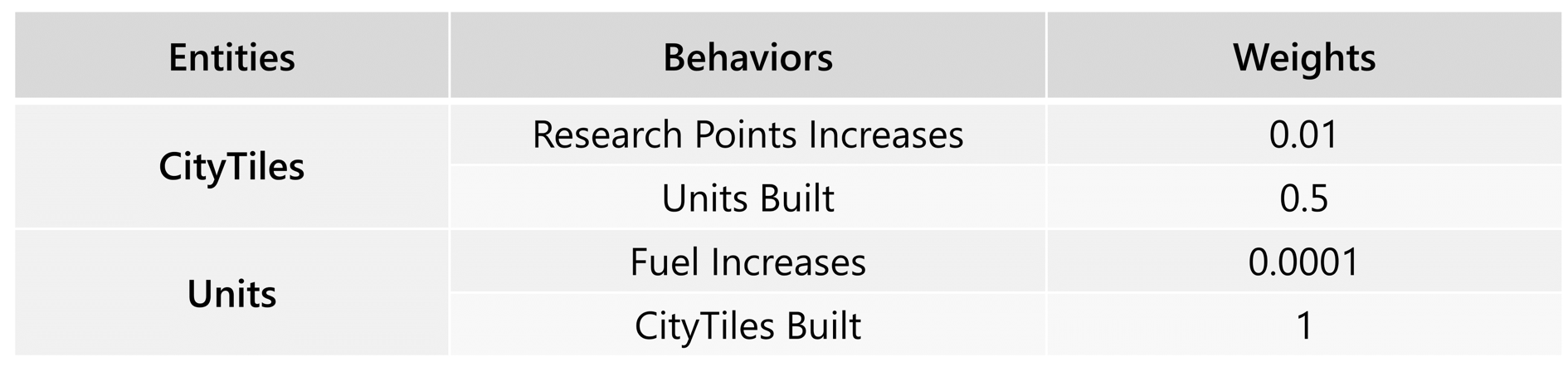 Table 1: Reward Weights for Four Behaviors of Units and City Buildings in the Team
Table 1: Reward Weights for Four Behaviors of Units and City Buildings in the Team
| Phase 2: Sparse Rewards with Learning Signals
After Phase 1, we implemented sparse reward schemes, such as providing rewards based only on the final match results, to encourage agents to explore unexpected behaviors that could lead to victory. However, directly assigning ±1 rewards based on win/loss outcomes does not facilitate effective exploration. To address this, we improved the learning signal as follows:
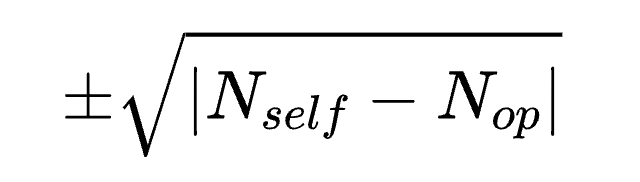
Where Nself represents the final number of city buildings at the end of the game, and Nop represents the final number of opponent's city buildings.
| Phase 3: Sparse Rewards
To elevate the performance ceiling of the agents, we removed the manually designed learning signals from Phase 2 and only implemented win/loss-related sparse rewards. We observed that as the number of training steps increased, the agents' strategies evolved accordingly.
Evolution of AI
To illustrate the evolution of our agent strategies, we present excerpts from match videos at each of the four phases mentioned above. In these recordings, our agents compete against either themselves or the previous SOTA model, Toad Brigade (TB) [1].
Phase One: Novice Gatherers
Starting from scratch, our agents quickly mastered resource collection and city construction. However, at this stage, they hadn't learned to plan resource utilization effectively, and cities often struggled to survive due to the lack of resources, leading to a loss in the match.
| We vs TB
Our agent (yellow team) rapidly expanded its cities early game, but at the cost of depleting all wood resources in our half of the map. In contrast, the opponent (blue team) developed more sustainably and deployed units to invade our territory for resources. As a result, while our agent dominated early in the game, our energy supplies gradually diminished, limiting our city expansion. The TB team, relying on its rich energy reserves, caught up in the later stages.
Self-Play
In self-play scenarios, the over-expansion issue became more pronounced and intense, even emerging as the dominant strategy. Both our agents aggressively expanded from the very begining, leading to rapid resource depletion. When resource reserves became insufficient for city maintenance, large clusters of cities would vanish. Although the blue team won decisively, it was a matter of probability, and the same could have happened to them. All greed ultimately leads to destruction.
On a 32x32 map, while cities didn't collapse due to fuel depletion thanks to abundant resources, agents only learned the basic skill of building cities around resources without connecting them to reduce energy consumption.
Phase Two: Peace Lovers
As training progressed, our agents gradually learned to optimize city construction and achieve rational resource utilization. Additionally, the agents began to occasionally protect their resources from opponent raids. In this phase, agents learned several advanced strategies but remained focused on self-development, not yet learning to harass opponent territories.
| We vs TB
| Self-Play
Sustainable Development: Our agents learned to limit deforestation and allowed forests to regenerate, ensuring sustainability. Furthermore, when the opponent sent units to steal our resources in round 37, nearby workers immediately blocked their way, leading to a standoff that lasted for four rounds. However, the opponent eventually succeeded in invading our territory and stealing our resources. While our agents focused on their own development, the opponent performed better competitively, such as seizing resources from others.
Non-Aggression: The peace-loving agents achieved a win-win result in self-play. They protected trees and expanded cities rationally, showing impressive urbanization abilities. In this match, they almost built cities all over the map! However, this is a cruel zero-sum game where there can only be one winner. Seeking mutual benefit with the opponent only leads to defeat. When facing more aggressive agents, the peace lovers must learn to fight in order to win.
Phase Three: Visionary Planners
In this phase, our agents demonstrated aggressive strategies, like dispatching scouts to plunder opponents resources. Meanwhile, they also discovered better defensive strategies, for example, building cities in a straight line to prevent enemy invasion.
| We vs TB
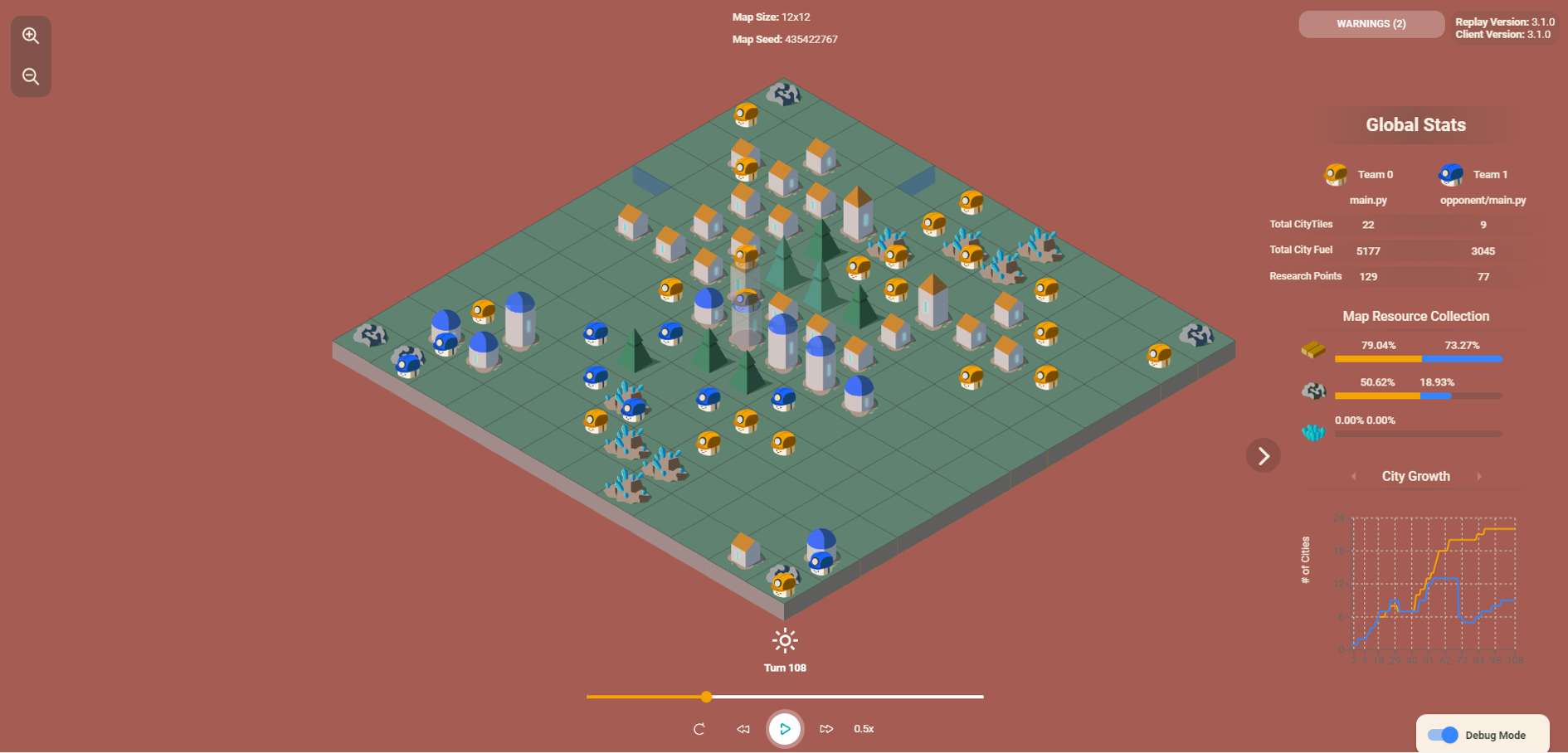
Building the "Great Wall": Initially, both sides were busy dividing territory and resources. Our agent (yellow) and the opponent (blue) adopted similar strategies: arranging city tiles in straight lines to prevent enemy entry, resembling the ancient Chinese "Great Wall".
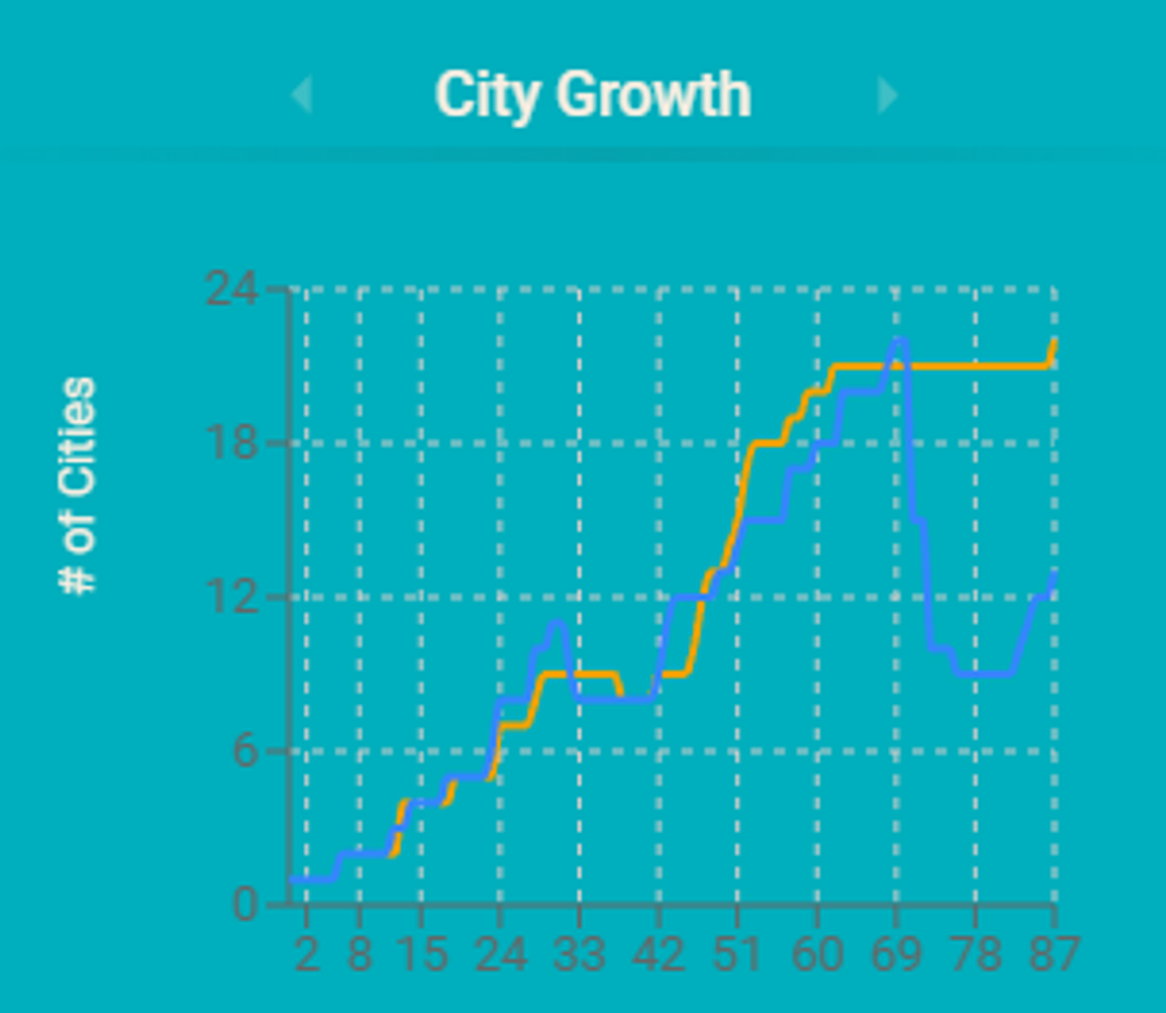 Balancing Resource Collection and Consumption: However, our agents excelled at balancing resource collection and consumption, never experiencing sudden city losses due to fuel shortages.
Balancing Resource Collection and Consumption: However, our agents excelled at balancing resource collection and consumption, never experiencing sudden city losses due to fuel shortages.
Seizing Opportunities: Once the opponent made a mistake, our agent quickly seized the opportunity. In round 71, after blue team cities fell, our agents sent several scouts deep into the blue team's territory to capture opponent resources, such as in rounds 157 and 170, contributing to our eventual victory.
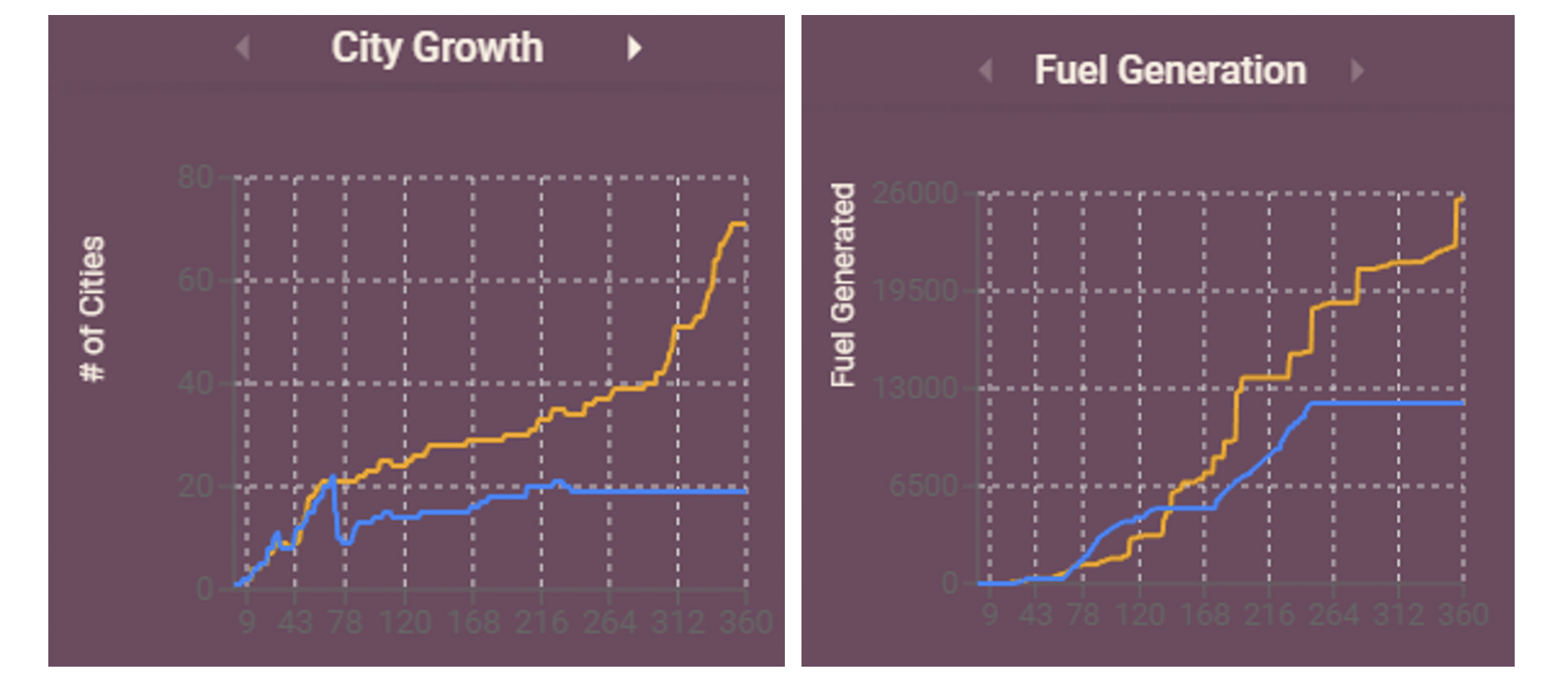 Resource Accumulation: Although both teams had only a slight difference in the number of cities initially, our team maintained a significant lead in fuel. This led to rapid city growth in the later stages and ultimate victory.
Resource Accumulation: Although both teams had only a slight difference in the number of cities initially, our team maintained a significant lead in fuel. This led to rapid city growth in the later stages and ultimate victory.
Resource Competition: Despite abundant fuel, our units continued competing for resources to prevent opponent's collection.
| Self-Play
In this match, we observed all aforementioned strategies in both teams. Since both agents used almost the same strategy, it was difficult to determine which one was better. However, the yellow team showed more aggression, invading the blue team's map starting from round 47, gaining more resources as a result. In the end, the blue team was confined to its own half of the map, while the yellow team was able to build cities in the blue team's territory. At this stage, the game became more like chess, where both global strategy and local decision-making were equally important.
Phase Four: Wise Decision-Makers
Ultimately, our agents demonstrated unexpected capabilities. Observed strategies were more complex and diverse than anticipated. Some strategies were even difficult for human players to understand or explain. In the final section, we will describe in detail the strategies employed by our agents.
| We vs TB
| Self-Play
Macro Strategy Analysis
As our agents continued to train and develop, the reasoning behind their actions became harder to explain. However, by analyzing the gameplay from the perspective of the player, we identified several outstanding strategies. Furthermore, when comparing the agents' match histories, these strategies showed a clear iterative evolution.
| Unit and City Building Layout
- In early training stages of training, city locations was random and unplanned. They were built near resources but were not connected to each other, so they could not share fuel. During this phase, agents typically showed no response to opponent sieges.
- Later, the agents gradually learned to construct cities in rows, columns, or even blocks. This kind of city building cluster exhibited higher survival rates compared to the earlier phase. By connecting cities, they could conserve fuel and surround resource nodes to prevent harassment from the opponent.
- An interesting detail emerged: agents would leave 1-2 rows of space between cities and map boundaries, positioning workers there. This allowed the agents to have more units available for movement, making attacks, defense, and various maneuvers quicker.
- Eventually, the agents learned to use different city layouts based on different situations. During attacks, especially in the early stages, the agents tended to build cities along a diagonal line to occupy the largest area of the map with the fewest buildings.
- Additionally, the agents became adept at using multiple workers to limit the opponent’s movement. In an impressive match, once our agents gained an advantage, they surrounded the opponent's cities with a dozen workers and used other workers to deliver fuel to keep these workers alive. This completely blocked the opponent’s city development. This was an incredibly flexible and meticulous strategy.
| Occupation, Harvesting, and Tree Conservation
In the early stages of training, our agents did not realize that trees were renewable resources. They simply treated trees as typical resources and gathered them as quickly as possible. Later, under the guidance of sparse rewards, this behavior changed. Three specific details stood out to us:
- First, the agents became aware of the need to preserve trees. They built a circle of cities around trees so that the trees could grow safely and be protected from the opponent's attacks.
- Second, the agents prioritized controlling trees in the map's center that were easily accessible to opponents. When effective control wasn't possible, the agents would quickly harvest them to limit opponent development.
- Finally, as the game neared its end, the agents would collect any remaining tree resources and build cities in those areas to maximize their score.
| Precise Fuel Calculation
- A surprising discovery in Phase 2 (Peace Lovers) was that our agents had very little fuel remaining at the end of the match, only in the hundreds or even tens. This meant that the agents made full use of almost all the resources available to them for construction, occupation, and transport, among other tasks. Simultaneously, to ensure the survival of all workers and cities, the agents refrained from building any extra units or city buildings due to greed or miscalculation. This process was very challenging because it involved real-time calculations of the resources consumed by all items and estimating their potential behavior. To some extent, human players would find it difficult to perform such complex and accurate calculations within the limited time between rounds.
- In the evaluations of Phases 3 and 4, as training continued, the above characteristics became less pronounced. I do not have an exact explanation for this phenomenon. Nevertheless, I believe the agents' ability to use the renewable tree resources and their more confident attacking behavior significantly contributed to this change, as they helped alleviate the resource scarcity dilemma.
Furthermore, during the evaluation process, we realized that, in addition to designing and utilizing a more reasonable network structure, the additional computational resources and longer training times in each stage of curriculum training might be another advantage we had over TB.
A notable phenomenon was that compared to TB's agents, which primarily learned during the first training phase, our agents tended to construct larger city clusters in the early stages.
| Initially, we could only observe the harmful impact of this strategy, namely, that it would exhaust nearby resources in the early stages of the game, including renewable trees, and use most of the acquired resources for city construction. As the game entered the latter half, map resources were either consumed or controlled by opponents, while established cities required substantial fuel to maintain survival. Consequently, our city structures would often vanish in darkness en masse.
| However, after completing various training phases, we were surprised to find that, as our agents gained a better understanding and planning of the entire game time and map space, the early massive city-building behavior, which we originally thought was a mistake, actually became an advantage for our agents.
| Specifically, more city structures in early-game meant our agents had more deployable units and available research points. Additional units enabled agents to control more resources across the map, particularly high-value resources like coal and uranium, as well as more map territory, providing sufficient space for late-game city expansion. More research points ensured agents could earlier acquire capabilities to collect and utilize advanced resources like coal and uranium, ensuring survival of units assigned to collect them. The control over resources and space provided by more early-game city tiles was a crucial factor in our agents' powerful performance.
Indeed, both our agents and TB's went through training phases guided by intensive rewards. Nevertheless, the above analysis indicates that our investment in additional training resources ultimately translated into superior city-building performance. Many details demonstrated the positive impact of more thorough training on agent capabilities. In the game, while our agents and TB agents may have similar strategies, it is clear that our agents are more aggressive while maintaining survival, better handling the finer details, and ultimately winning the game.
References
[1] Solution of Toad Brigade, No.1 of Lux AI Competition - Season 1.
[2] Grid-Wise Control for Multi-Agent Reinforcement Learning in Video Game AI. ICML 2019. Lei Han, Peng Sun, Yali Du, Jiechao Xiong, Qing Wang, Xinghai Sun, Han Liu, Tong Zhang.
[3] Proximal Policy Optimization Algorithms. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov.
[4] High-Dimensional Continuous Control Using Generalized Advantage Estimation. ICLR 2016. John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel.
[5] Deep Residual Learning for Image Recognition. CVPR 2015. Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.。